1、请先简单介绍一下您自己以及“拾贝 AI 科研助手”的核心功能。
我是zhtyyx,目前在上海,目前主业是在量化公司做开发,业余时间做全栈开发。
Shibei的主要功能:
- 自动采集论文:每天从 arXiv、PubMed 等数据源抓取最新论文,支持计算机、医学等多个学科;
- AI 智能解读:接入通义千问、百川等 AI 模型,自动生成论文摘要和关键词,快速了解论文核心内容;
- 深度研究对话:可以针对论文内容提问,AI 会结合相关论文给出答案,支持多篇论文联合分析;
- 知识图谱:根据作者、关键词、研究主题自动构建知识网络,帮助发现研究之间的关联;
- 个性化推送:设置感兴趣的领域和关键词,系统每天通过邮件推送相关论文;
- 论文管理:支持收藏、筛选、标签分类,方便整理和查找论文;
观猹产品:https://watcha.cn/products/shi-bei-ai-ke-yan-zhu-shou
2、做这个产品的灵感来源是什么?
这款应用源于两个生活中的痛点:
第一是我以前在四大和投行任职过程中,发现很多专业人士,希望能够保持专业,从垃圾信息中抽离出来,也有看论文的需求,但是每天时间太少。
第二是我注意到三甲医院或者高校,想要晋升,都有写论文的需求,但是想要捕获灵感,或者不写重复的论文,需要每天去了解业内最新进展。
我就在想,如果我能帮到这些专业人士和医生就好了,在 AI 大模型发展得如此先进的今天,拾贝有了诞生的土壤。
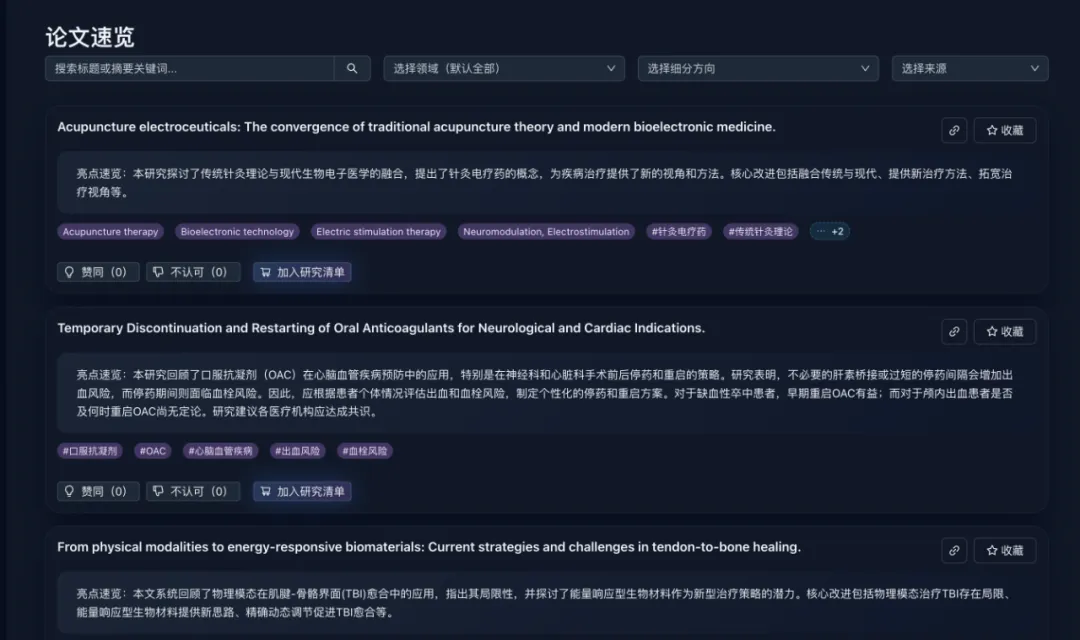
3、在“自动采集论文”方面,我留意到你们目前是接入了 arXiv、PubMed 等数据源,不同学科的抓取逻辑和更新频率是怎样的?未来是否考虑接入更多中文数据库?
目前其实还在补齐历史数据的阶段,抓取逻辑主要是通过 openapi,新论文出现后基本上能够做到第一时间进行更新,未来打算接入更多的中文数据库,远期目标是集成 2 亿+论文、2000 万+活跃学者信息,但现在只有我一个人,各方面资源有点欠缺,所以还需要时间构建强大的底层学术数据库。
4、拾贝的一大特色是 AI 自动生成论文摘要和关键词,论文页面还允许用户标记“有用”或“无用”,这个反馈后续会产生哪些影响?以及你们是如何评估与优化摘要质量的?
在我的设计中,我希望把又新又有帮助,有突破的论文放到更前面让大家第一时间看到,但当前还是以新为主。这个标记是未来互动的入口,我期待看到未来有用户在论文下面就某篇论文撕起来,哈哈
关于 AI 对论文展开摘要,我是设计了多个 agent,类似于一个评价小组,也会有督察员,我会不断的提升摘要质量。
5、与普通的大模型对话相比,“深度研究对话”的功能有哪些针对科研场景的改良吗?
主要是不瞎聊。 我会针对不同领域选模型,比如医疗类论文,我就倾向用百川这种在垂直领域微调过的模型,准确率会高很多。而且在流程上做了限制,让 AI 必须结合论文内容回答。
其次,多 agent 编排的时候也会注意对科研场景做一些定制化的优化。
6、产品目前是完全免费,未来是否有商业化计划?
继续免费,没有商业化计划,我现在的心态就是花鸟鱼虫市场买了一些小鱼苗,撒到池塘里,慢慢长吧
如果有对这个产品感兴趣的大佬,也可以随时通过观猹联系我,可以一起搞事情。
7、10分满分的话,你愿意给你的产品打几分?理由是?
说 6 分是对自己的心血有感情,但要做的太多了,推荐机制,讨论机制,论文爬取效率,摘要优化……
从创意来说可以给自己打 8 分。
8、除了自己的产品,你还有在用哪些产品?
我用的太多了
coding: claude code + codex + cursor + antigravity + kilo
网站: linux.do 重度用户,即梦 AI,Gemini 重度用户,github
9、你有哪些工作/生活习惯?
我是自动化狂魔,喜欢研究各种自动化,因为现代信息量太大,要做的事情太多,人必须建立自己的自动化处理系统,也就是第二大脑。
我自己搞了一套家里的安防系统,也有自己的信息流处理系统,家庭管理系统。
10、最后,请用一句话打动用户并让她使用你的产品
每天五分钟,帮你成为世界级专家。